Audio evaluator, field recordist, annotation specialist, sound designer, and AI data reviewer working across generative audio evaluation, human-made music datasets, field/audio capture, UI workflow review, and evidence-based QA.
BAURU, BRAZIL / UTC-3 / REMOTE CONTRACTOR / EN C2 + PT-BR NATIVE
Four voice samples with raw and processed versions, demonstrating English technical narration, conversational delivery, expressive reading, and native Brazilian Portuguese. Recorded with Audio-Technica AT2020, M-Audio M-Track Solo, and edited/exported in FL Studio.
01 / Technical NarrationEN / 48kHz / 24-bit WAV
Neutral English narration demonstrating clarity, pacing, pronunciation, and technical delivery.
Raw
Processed
02 / ConversationalEN / 48kHz / 24-bit WAV
Natural English explanation style, showing spoken clarity, timing, and less formal delivery.
Raw
Processed
03 / ExpressiveEN / 48kHz / 24-bit WAV
Expressive read demonstrating tone control, atmosphere, and dynamic vocal presence.
ResultReduced harshness and more controlled transient behavior
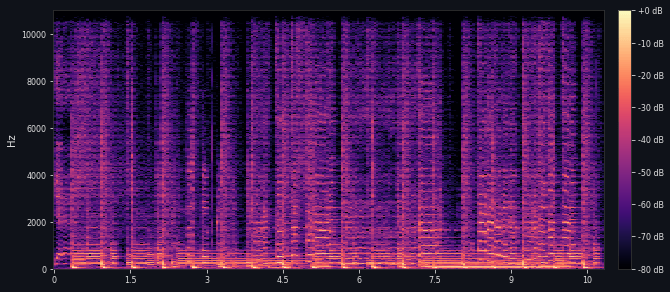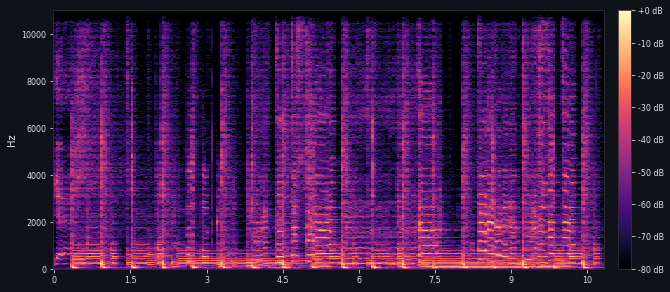
04 / AI Audio Shimmer / Hiss48kHz / 24-bit WAV
Before
After
ProblemAI-generated audio with high-frequency shimmer / hiss
ProcessDenoising pass followed by spectral artifact check
ResultReduced high-frequency haze while preserving the main spectral structure
Compare the frequency content before and after denoising. Shimmer appears as diffuse haze in the high frequencies; after denoising, that haze is visibly reduced while the main harmonic and transient structure remains largely preserved.
Tools / WorkflowFL Studio editing/export, denoising/restoration processing, spectrogram-based artifact review
Specs48kHz / 24-bit WAV
NoteBefore/after files are short comparison excerpts.
03 /
Audio Annotation & Technical Evaluation Sample
Structured annotation and technical evaluation of an unreleased human-made production excerpt, combining timestamped segmentation, instrumentation tagging, vocal-sample treatment notes, mix behavior, measured fidelity review, and evaluation-style technical annotation.
The excerpt develops from a chopped spoken-word interview intro into a filtered 808-driven electronic beat, using gating, reverse edits, cut-and-repeat phrasing, synth pads, bell-like synth details, and LFO-driven synth-bass movement.
Technical Behavior
The intro is more open and midrange-forward, while the beat sections are moderately compressed, center-focused, and low-end dominant, with the strongest measured low-frequency focus around 64.6 Hz.
Evaluation Focus
The main production signature is the transformation of spoken-word material into rhythmic and musical texture. The main technical flag is peak/headroom: true peak reaches around +1.2 dBFS, so the file is not broadcast-safe without correction.
This document presents a structured audio annotation of an unreleased 2016 production excerpt, combining musical segmentation with measured technical review. Integrated loudness is estimated at -8.6 LUFS, with 9.0 LU loudness range and true peak around +1.2 dBFS. The mix is narrow-to-moderate, center-focused, and mostly mono-compatible by correlation, with controlled transients and no proven sustained clipping, codec artifacts, or phase problems. Overall fidelity is best described as clean demo / mid-tier production, with a clear note that peak/headroom correction is needed before broadcast-safe delivery.
Original sound design and production excerpt in a breakcore-influenced experimental electronic style. The piece combines bass design, synth/FM texture, processed voice material, fast breakbeat edits, dense rhythmic programming, and club-oriented low-end pressure.
Original Production ExcerptMP3 / breakcore-influenced experimental electronic
Source
Original production excerpt by Lucas Fernandes Nascimento
Breakcore-influenced drum programming, fast breakbeat edits, dense rhythmic movement, bass pressure, and high-energy arrangement.
05 /
Evaluation Rubrics
Framework for Evaluating Audio Quality in Generative ModelsPDF preview / rubric discipline
Evaluating generative audio is different from evaluating finished records. You're not judging a final product -- you're judging a model's attempt to produce one. This framework is the working discipline I apply across audio evaluation and annotation workflows, holding two frames at once: is this good audio, and is this a good output given what was asked.